世仇与旧友:小说中动态关系的无监督学习
这是一篇翻译文章。原文作者是 Mohit Iyyer 等人。
原文链接
Feuding Families and Former Friends: Unsupervised Learning for Dynamic Fictional Relationships
摘要
理解小说中两个角色之间的关系如何随着时间变化 (比如从最好的朋友变成死敌) 是数字人文里的一个重要挑战。我们为这个任务引入一种新的非监督神经网络,利用了词典学习来生成可解释且精确的关系轨迹。之前描述文学关系的工作依赖于用预先规定好的标签标注过的情节概要,而我们的模型从小说原文数据集学到一系列全局关系描述符以及每种关系描述符的演化轨迹。我们的模型学到了事件的描述符 (比如婚姻或谋杀),以及人际状态描述符 (比如爱与悲伤)。我们的模型在两个众包任务上超过了基准话题模型,并且我们发现了与一个已有的数据集里的标注之间有意思的相关性。
1. 描述角色关系
当书中两个角色分面包时,他们的这一餐仅仅是为了吃东西,还是意味着更多? Cognard-Black et al. (2014) 认为这种简单的互动反映了角色的多样性和背景,而 Foster (2009) 认为一顿饭的气氛可以预示一本书余下部分的走向。为了支持这些理论,学者们用他们的文学专长在不同书之间建立联系: 乔伊斯的《往生者》中 Gabriel Conroy 在一次奢华宴会上与他家庭的不和谐音,《思家饭馆》中 Tyler 母亲的沮丧,以及 Carver 的《大教堂》里对吃肉糕的盲人的不情愿的尊重。
然而,这些洞察来之不易。经年累月的细致阅读和内化才能在书籍之间建立联系,这意味着关系的对称性和原型很可能继续隐藏在每年出版的成千上万本书中,除非文学专家主动地去搜集这些关系。
自然语言处理技术可以发现文本中的模式 (Jockers, 2013),被越来越多地用来辅助文学研究。第 6 节我们回顾已有的利用固定标签分类或聚类书中角色关系 (朋友或敌人) 的技术。但这些技术忽略了不在已有语汇中的角色互动,并且不能处理关系在一本书的进程中演化动态性,比如 the vampiric downfall of Lucy and Arthur’s engagement in Dracula (图 1) or Winston Smith’s rat-induced betrayal of Julia in 1984.
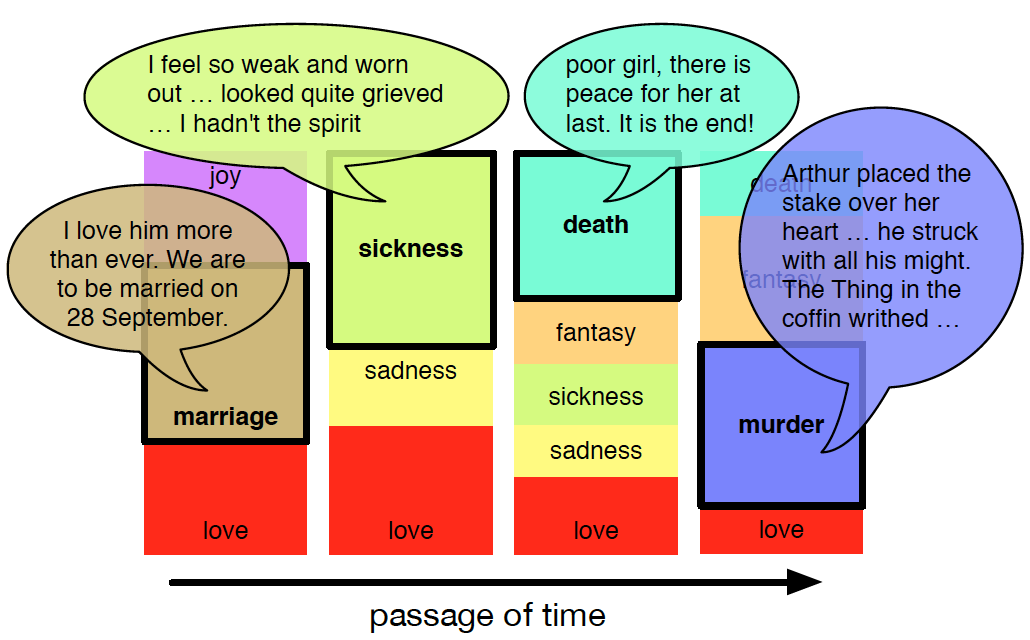
图 1: 描述关系动态演化轨迹的示例。目标是在无监督的前提下从虚构文学作品的原始文本学到描述符及其演化轨迹。
为了处理这个问题,我们提出非监督关系模型的任务,让模型为每对文学形象同时学习关系描述符集合以及关系演化轨迹。不同于赋予一个特定关系单个描述符,我们的模型学到的轨迹是一个描述符序列 (图 1)。
Gruber et al. (2007) 的贝叶斯隐含话题马尔可夫模型 (HTMM) 自然成为我们这个任务的选择,因为它可以计算关系描述符 (以话题的形式),且有额外的时间成分。但是我们的实验表明 HTMM 学到的描述符会不自洽,且等多关注于事件和环境 (比如饭局,室外) 而不是人际状态如喜悦和悲伤等。
受近期深度学习进展的鼓舞,我们提出关系模型网络 (RMN),一个深度复现自动编码器的新变种,引入词典学习来学习关系描述符。在两个众包评价上 RMN 取得了比 HTMM 和别的话题模型基准更好的描述符一致性和轨迹精度 (第 4 节)。第 5 节讲了定性结果并与已有的文学研究建立了联系。
2. 一个角色互动数据集
我们的数据集包含来自 Project Gutenberg 和其它网络来源的 1383 部虚构作品。前者包含有限的主要是古典的文学作品 (不含科幻),所以我们加了更多的不同风格的当代小说 (推理,言情,奇幻)。
为了识别角色提及,我们运行了 Book-NLP 流程 (Bamman et al. 2014);这流程包含角色名字聚类,被引用角色的识别,以及共同指代的分辨。对每个检测到的角色提及,我们定义一个跨越提及之前 100 个和之后 100 个词的区间。我们没有使用句子或段落的边界,因为不同作者之间差别很大 (比如 William Faulkner 的单句经常比 Hemingway 的段落还长)。我们数据集里的所有区间都包含刚好对两个角色的提及。这是个相当严格的要求,强制减小了数据量,而包含多于两个角色的区间一般噪音较多。
识别出可用的区间后,我们过滤掉那些少于五个区间的关系。不这样做的话,我们的数据集会被不重要角色的短暂关系占据;这是不想要的,因为我们关注的是长期的、可变的关系。最后,我们过滤了词库,删掉了 500 个最常见的词语,以及那些在少于 100 本书中出现的词语。后一个步骤帮助纠正时间阶段和流派导致的变化 (e.g., “thou” and “thy” found in older works like the Canterbury Tales)。最终的数据集包含 20013 个关系和 380408 个区间,而词库包含 16223 个词。
3. 关系模型网络
本节给出将 RMN 用于关系模型的数学描述。我们的模型在思想上跟话题模型类似:给定一个输入数据集,RMN 的输出是关系描述符 (话题) 集合,以及——对数据集中的每个关系——一个轨迹,或者一系列这些描述符的概率分布 (文档-话题分派)。然而,RMN 使用了深度学习来更好地控制描述符一致性和轨迹平滑性 (第 4 节)。
3.1 问题的形式化
假定 \(b\) 这本书里有两个角色 \(c_1\) 和 \(c_2\)。定义 \(S_{c_1,c_2}\) 为由词语区间组成的序列,其中每个区间 \(S_t \in S_{c_1,c_2}\) 本身也是词语组成的集合 \(\{w_1, w_2, \ldots, w_l\}\),包含对 \(c_1\) 和 \(c_2\) 的同时提及;这里 \(l\) 是固定的。换句话说,\(S_{c_1,c_2}\) 包含每个 \(c_1\) 和 \(c_2\) 同时出现的场景对应的文本,且按时间顺序排列。
3.2 模型描述
与其它用于自然语言处理的神经网络模型一样,一开始我们为每类单词 \(w\) 赋予一个实向量嵌入 \(v_w \in \mathbb{R}^d\)。这些嵌入是 \(V\times d\) 矩阵 \(\mathbf{L}\) 的行,\(V\) 是词库大小。类似地,角色和书有自己的嵌入矩阵 \(\mathbf{C}\) 和 \(\mathbf{B}\)。我们希望 \(\mathbf{B}\) 抓住全局上下文信息 (比如 “Moby Dick” takes place at sea),而 \(\mathbf{C}\) 抓住角色的那些不因所处关系而变的方面 (比如 Javert is a police officer)。最后,RMN 还学习到关系描述符的嵌入,这需要大小为 \(K\times d\) 的矩阵 \(\mathbf{R}\),这里 \(K\) 是描述符的个数,类似于话题模型中话题的个数。
每个 RMN 的输入是一个元组,包含一本书和两个角色的编码,以及对应他们关系的区间:\((b, c_1, c_2, S_{c_1,c_2})\)。对每个这样的输入,目标是从通过 \(\mathbf{R}\) 里的关系描述符的线性组合重构 \(S_{c_1,c_2}\);参见图 2。我们现在正式描述这个过程。
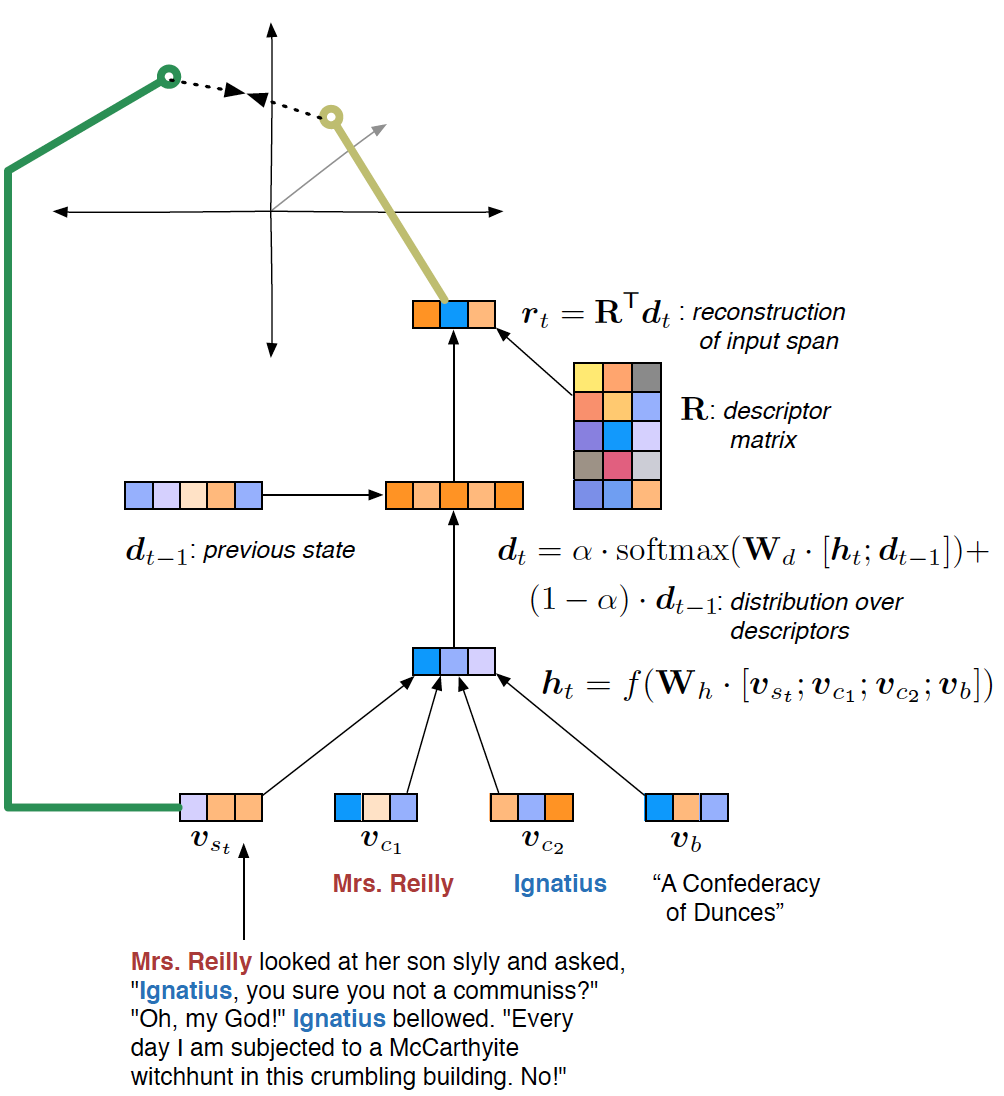
图 2:RMN 单次计算的例子。模型用 \(\mathbf{R}\) 里描述符的线性组合来近似一个输入区间 \(v_{s_t}\) 的矢量覆盖。描述符权重 \(d_t\) 定义了每个时间点的关系状态——当视为一个序列时——构成一个关系轨迹。
3.2.1 用矢量平均模拟区间
\(S_{c_1,c_2}\) 里的每个区间 \(s_t\) 的矢量表达通过其中所有词的矢量的平均来计算 \[ v_{s_t} = \frac{1}{l}\sum_{w\in s_t} v_w. \] 然后我们把 \(v_{s_t}\) 与角色嵌入 \(v_{c_1}\) 和 \(v_{c_2}\) 以及书嵌入 \(v_b\) 拼接到一起形成一个大矢量,输入给标准的前馈层并得到隐含态 \(h_t\), \[ h_t = f(W_h \cdot \left[v_{s_t}; v_{c_1}; v_{c_2}; v_b\right]). \] 在所有实验中,变换矩阵 \(\mathbf{W}_h\) 都是 \(d\times4d\) 维。我们把 \(f\) 取为 \(\mathrm{ReLu}\) 函数:\(\mathrm{ReLu}(x) = \mathrm{max}(0,x)\)。
3.2.2 用关系描述符来近似区间
有了区间的表示,我们就来通过词典学习 (Olshausen and Field, 1997; Elad and Aharon, 2006) 的一个变型来学习描述符,这里描述符矩阵 \(\mathbf{R}\) 是词典,而我们试图用词典里条目的线性组合来近似输入的区间。
假定我们对 \(S_{c_1,c_2}\) 里的每个区间 \(s_t\) 计算隐含态。给定一个 \(h_t\),我们利用某种复合函数 \(g\) 计算一个针对 \(K\) 个关系描述符上的权重矢量 \(d_t\);\(g\) 在下节讲。概念上,每个 \(d_t\) 是个关系状态,而一个关系轨迹是一系列时间排序的关系状态 ( 图 1)。计算了 \(d_t\) 后,我们用下面的加权平均来计算重构矢量 \(r_t\): \[ r_t = \mathbf{R}^\mathsf{T} d_t. \] 我们的目标是让 \(r_t\) 与 \(v_{s_t}\) 相似。我们使用一个对比性的最大边界目标函数 (Weston et al., 2011; Socher et al., 2014)。我们从数据集中随机取出一些区间并计算每个取出的区间的矢量平均。这个区间矢量组成的子集记为 \(N\)。未正规化的目标函数 \(J\) 是个 Hinge loss 函数,它最小化 \(r_t\) 和阴性样本 (即随机取出的样本) 的内积,同时最大化 \(r_t\) 和 \(v_{s_t}\) 的内积, \[ J(\theta) = \sum_{t=0}^{|S_{c_1,c_2}|} \sum_{n\in N} \max(0, 1 - r_t v_t + r_t v_{s_n}), \] 这里 \(\theta\) 是模型参数。
3.2.3 计算描述符上的权重
应该选取何种复合函数 \(g\) 来表达给定时间点的关系状态?表面上看,这显得简单;我们可以把 \(h_t\) 投影到 \(K\) 维,然后使用 \(\mathrm{softmax}\) 或别的非线性函数来得到非负权重 (我们试了不同的非线性函数,发现 \(\mathrm{softmax}\) 给出的结果最有可解释性,因为它倾向于选出单个的描述符)。但是,这个方法忽略了前一个时间点的关系状态。为了模拟关系对时间的依赖,我们可以添加一个复现连接, \[ d_t = \mathrm{softmax}(W_d \cdot \left[h_t; d_{t-1}\right]), \] 这里 \(W_d\) 的大小是 \(K\times(d+K)\),而 \[ \mathrm{softmax}(q) = \frac{e^{q}}{\sum_{j=1}^k e^{q_j}}。 \]
我们希望这个复现连接可以把过去关系中的一部分携带到当前时间点。在时刻 \(t\) 相爱的两个人不大可能在时刻 \(t+1\) 分手,就算 \(s_{t+1}\) 不包含任何跟爱有关的词。但是,由于目标函数最大化的是与当前时刻的输入的相似性,模型并没有被强迫从前一个状态到当前状态是平滑过渡。一个补救措施是让模型预言下一个时刻的输入,但发现这样很难优化。
我们于是通过修改上面的方程来强迫模型使用上次的关系状态 \[ d_t = \alpha \cdot \mathrm{softmax}(W_d \cdot \left[h_t; d_{t-1}\right]) + (1-\alpha) \cdot d_{t-1}, \] 这里 \(\alpha\) 是 0 到 1 之间的数。我们试过把 \(\alpha\) 固定为 0.5,以及让模型通过下面的关系来学习 \(\alpha\) \[ \alpha = \sigma\left(v_\alpha^\mathsf{T} \cdot \left[h_t;d_{t-1};v_{s_t}\right]\right), \] 这里 \(\sigma\) 是 sigmoid 函数,而 \(v_\alpha\) 是一个 \(2d + K\) 维的矢量。最开始固定 \(\alpha=0.5\) 然后在别的参数收敛后在调节 \(\alpha\) 可以提到训练的稳定性;关于超参数参见第 4 节 (参考了词典学习中的 alternative minimization 策略,其中词典和权重分开学习。参考 Agarwal et al., 2014)。
3.2.4 解释描述符并强化唯一性
每个描述符是 \(\mathbf{R}\) 的 \(d\)-维行矢量。由于我们的目标函数 \(J\) 强制这些描述符跟单词嵌入 \(\mathbf{L}\) 处于同一个矢量空间,我们可以用余弦距离查看 \(\mathbf{L}\) 中的近邻矢量来做出解释。
为了避免描述符之间过于相似,我们又添加了一个惩罚项 \(X\): \[ X(\theta) = \left\lVert\mathbf{R}\mathbf{R}^\mathsf{T} - \mathbf{I}\right\rVert, \] 这里 \(\mathbf{I}\) 是单位矩阵。这个项来自独立成分分析中分量的正交性约束 (Hyvarinen and Oja 2000)。\(\mathbf{R}\) 的行向量之间越接近正交,则 \(X\) 越小。
我们把 \(J\) 和 \(X\) 加到一起得到最终的训练目标 \[ L(\theta) = J(\theta) + \lambda X(\theta), \] 这里 \(\lambda\) 是控制唯一性惩罚的强度的超参数。
4. 评估描述符和轨迹
由于以前还没有工作探究非监督关系模型随时间的可解释性,对 RMN 不太好评估。更大的问题是这个任务本来就有主观性,比如,一个漏掉了重大事件的轨迹是否比幻想出原文不存在的情节的轨迹更好?
注意到这些问题,我们进行了三轮评估来说明我们的输出是合理的。首先,我们进行了众包可解释性实验,结果表明 RMN 给出的描述符比三个话题模型基准的更一致。第二个众包任务表面我们的模型产生的轨迹比话题模型更符合情节概要。最后,我们定性比较了 RMN 的输入和已有的对文学关系的静态标注,发现了预期的和令人吃惊的结果。
4.1 话题模型基准
在进入评估之前,我们简单描述一下三个基准方法,它们都是贝叶斯生成模型。隐含狄利克雷分派 (LDA; Blei et al. 2003) 为每个文档学到单个文档-话题分布;我们可以通过把一个关系的所有区间拼接成一个文档来把 LDA 应用到我们的数据集。类似地,NUBBI (Chang et al. 2009a) 为关系和单个角色分别学到话题集。
LDA 和 NUBBI 不能处理区间的时序,因为它们把所有关系视为可以互换的。我们可以把这些方法学到的描述符与 RMN 的比较,但我们不能评估它们的轨迹。我们转向隐马尔可夫话题模型 (HTMM; Gruber et al. 2007),这个模型抛开了 LDA 和 NUBBI 的词包假设,而把文档中的话题段落看作马尔可夫链。这个模型对每个文档输出平滑的话题序列,因此可以跟 RMN 的输出比较。
4.2 实验设置
在我们的描述符解释性实验中,我们对所有模型改变描述符 (话题) 的个数 (\(K=10,30,50\))。我们用 100 次迭代训练 LDA 和 NUBBI,采用了 collapsed Gibbs sampler,而 HTMM 采用了通常默认的 100 EM 迭代设置。
对于 RMN,我们把单词嵌入矩阵 \(\mathbf{L}\) 初始化为 300 维的基于 Common Crawl 训练出的 GloVe 嵌入 (Pennington et al. 2014)。角色和书嵌入 \(\mathbf{C}\) 和 \(\mathbf{B}\) 随机初始化。训练的前 15 个阶段 \(\alpha\) 固定为 0.5; 当描述符矩阵 \(\mathbf{R}\) 收敛后,我们固定 \(\mathbf{R}\),然后在接下来的 15 个阶段细调 \(\alpha\)。由于话题模型基准不能获取角色和书的元信息,为了比较的公平,我们训练了一个“一般性”的 RMN (GRMN),其中元信息嵌入被从计算 \(h_t\) 的方程移除了。唯一性惩罚 \(\lambda\) 设为 \(10^{-4}\)。
除了 \(\mathbf{L}\) 之外所有的 RMN 模型参数都通过 Adam (Kingma and Ba 2014) 优化,30 个阶段的学习率取为 0.001;单词嵌入在训练中没有精细调节。我们也针对输入区间使用了 word dropout (Iyyer et al. 2015),以 0.5 的几率从矢量平均计算中移除单词。
4.3 描述符有意义吗
第一个实验的目的是比较 RMN 学到的描述符和话题模型基准学到的话题。我们进行了单词侵扰实验 (Chang et al. 2009b):给定一个单词,工作人员从一个单词集合 (不包含给定单词) 中识别出一个来自相同话题的“侵扰”单词。对于话题模型,同一个话题的五个最可能的单词中被加入了来自另一话题的高概率单词。对 RMN 和 GRMN 采用相同的处理,除了用描述符嵌入的余弦距离代替话题概率之外。为了训练过程的控制随机性,我们对每个模型训练三遍,所以最后的实验包含 1350 个任务 (每次实验 \(K=10,30,50\) 个描述符,每个模型三次实验)。
我们使用 Crowdflower 平台从十个工作人员处收集每个任务的评判。我们的评价度量 —— 模型精度 (MP) —— 定义为对每个描述符 \(k\) 选出正确入侵单词的工作人员比例。较低的模型精度提示描述符缺乏一致场景。
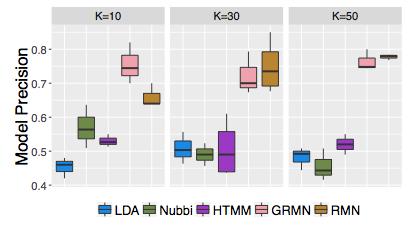
图 3: 单词侵入实验的模型精度。RMN 比别的高。
平均看来,RMN 的描述符比基准的可解释性好,对所有 \(K\) 值达到 0.73 的平均模型精度 (图 3)。三个话题模型基准的模型精度都差不多,在 0.5 附近徘徊。GRMN 和 RMN 之间差异很小;但是,图 6 对学到的角色和书嵌入的可视化可能会对文学学者有用。表 1 列出了 RMN 和 HTMM 的高精度和低精度描述符的例子。完整列表在附加材料中。
图 6:
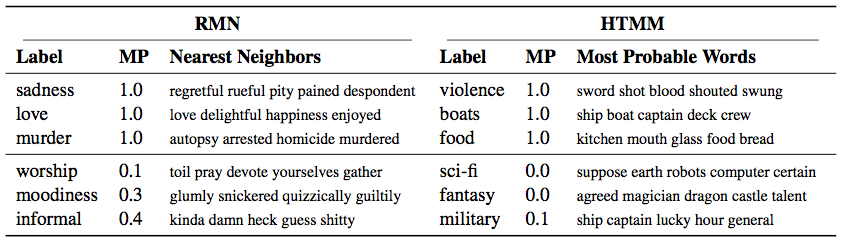
表 1:
4.4 演化轨迹有意义吗
上面的评估只关注了描述符的质量,我们下一个实验比较通过侵入实验得到的最佳 RMN 轨迹和最佳 HTMM 轨迹。工作人员阅读情节概要,然后选出描述给定关系的演化比较好的模型。我们采用 \(K=30\) 的设置,因为它在描述符的多样性和轨迹的可解释性之间达到最佳平衡。
为这个评估我们爬取了维基百科,Goodreads,SparkNotes,用来对 1383 本书做情节概要。然后移除那些包含的角色在概要中提及次数不到 5 次的关系,最后得到 125 个关系用来做最终评估。对每个工作人员我们展示两个角色,一个情节概要,以及通过 RMN 和 HTMM 学到的轨迹的可视化 (图 4)。工作人员选出最符合情节概要的关系轨迹。

图 4: Crowdflower 概要匹配任务的例子。工作人员需要选择最符合 Siddartha 与 Govinda 之间关系演化的轨迹。左边是 RMN,右边是 HTMM。
为了生成可视化,我们先让一个外部人员用表 1 中的单个词语标注两个模型里的每个描述符。为了公平,标注者不知道背后的模型是什么。对于 RMN,我们通过展示在每个时刻 \(t\) 的权重矢量 \(d_t\) 的最大分量对应的标签来可视化。对于 HTMM 类似,我们展示每个时刻最可能的话题。
每个比较用了七个工作人员,结果倾向于 RMN:125 个评价过的关系中,工作人员认为 87 个由 RMN 给出的结果更好。我们计算了 Fleiss 的 \(\kappa\) 值 (Fleiss 1971) 来修正标注者之间的巧合因素,发现 \(\kappa=0.32\),表明工作人员之间还是相当一致的。进一步,34 个关系在七个工作人员之间是没有分歧的,而其中 26 个毫无疑问地倾向于 RMN。
4.5 什么让关系成为正面关系
RMN 可以辅助在不同书和流派之间建立联系。作为这个方向的第一步,我们探究了是什么让一个关系成为正面或负面关系,方法是把 RMN 和 HTMM 给出的轨迹与近期发布的关于小说关系的静态类同标注 (Massey et al. 2015) 比较。有些相关性是预期的,比如,谋杀与悲伤是强负面描述,也有令人吃惊的,比如政治是负面的,而宗教是正面的。
Massey et al. (2015) 的类同标记要求工作人员把一个关系描述为正面、负面,或者中性。我们只考虑两个标注者意见一致的非中性关系,移除所有我们数据集没有的书。这样剩下了 120 种关系,其中78% 是正面,其余是负面。
由于标注是静态的,我们把所有时间的关系轨迹聚合到一起。对所有标注为特定属性的关系,我们把所有时间的 RMN 的关系状态 \(d_t\) (注意 \(d_t\) 是关系的权重矢量,代表某一时刻的关系的可能性) 和 HTMM 的文档-话题分布计算了平均,由此得到 K 维的“平均正面”和“平均负面”权重矢量 \(a_p\) 和 \(a_n\)。然后计算矢量差 \(a_p - a_n\) 并排序,得到一个描述符的有序列表,其中有正的差异的描述符更多地出现在正面关系中。表 2 列出了最正面和最负面的描述符;特别有意思的是两个模型都为政治关系给出了大的负面权重。

表 2:
5. 定性分析
是什么让 RMN 比基准话题模型在可解释性和轨迹准确度上好?这里我们分析 RMN 和 HTMM 的相似性,并看看让 RMN 成功和失败的定性例子。我们也在类同性实验中的发现和已有的文学研究之间建立了联系。
两个模型在学习和指派基于事件的描述符 (比如犯罪,暴力,食物) 时都很不错。具体地,RMN 和 HTMM 在环境描述符和图形化性场景上一致 (图 5 中间部分)。
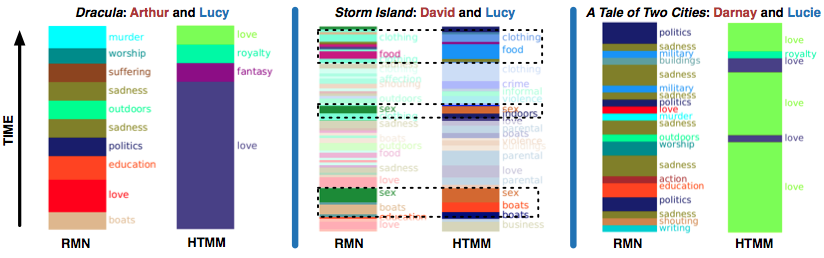
图 5:
然而,RMN 更擅长人际关系。基准话题模型未能学到负面情感描述符,比如悲伤和受苦,这解释了图 5 最左边为什么 HTMM 关于 Arthur 和 Lucy 的轨迹不准确。所有的基准话题模型学到重复的话题;表 2 中,一个关于爱的描述符是强烈正面的,而另一个重复的描述符是强烈负面的。RMN 通过唯一性惩罚绕过了这个问题。
虽说描述符多样性的提高是个好事,但有时这也让 RMN 迷失。它很大程度上忽视了狄更斯《双城记》中 Charles Darnay 和 Lucie Manette 之间的爱情,因为这本书的语调是哀伤的;而 HTMM 的轨迹虽然很简化,却发现了这段罗曼史 (图 5 右边)。虽然 RMN 的可习得的书和角色嵌入本应提供帮助,但区间内的信号未能导致恰当的描述符。
RMN 和 HTMM 都学到政治是非常负面的 (表 2)。已有的研究支持这个发现:比如,维多利亚时代的作者“沉迷于陈旧的社会与法律习俗的、以及独裁与专横政府的,相异性” (Zarifopol-Johnston 1995),而科幻小说中“反乌托邦 —— 因为它比乌托邦与现实经验共同点更多” (Gordin et al. 2010)。我们的类同性数据主要来自维多利亚时代的小说 (比如狄更斯和艾略特的),这让我们相信我们的模型的表现是合理的。最后,关于第一节提到的饭局的“额外”意义,食物略微倾向于出现在正面关系中。
6. 相关的工作
我们的工作主要建立在两个领域的基础上:计算文学分析和用于自然语言处理的深度神经网络。
多数之前的计算文学分析工作要么聚焦于角色,要么聚焦于事件。前一类中,图模型和分类器被用来从小说和电影情节概要中学习角色的人格。NUBBI 模型学习的是角色以及角色之间关系的统计性话题描述。这些模型缺乏时间成分。
于我们工作最接近的是 Chaturvedi et al. (2016) 的监督式结构化预测问题,其中特征被设计得可以预测情节概要中两个角色得正面和负面互动。其它研究包括从小说和电影构建社会网络 (Elson et al., 2010; Srivastava et al., 2016),以及努力总结和生成故事 (Elsner 2012)。
虽然我们的模型学到的关系描述符有些是以角色为中心,但另外一些是以事件为中心的,描述了行动而不是感受。这些描述符是之前许多工作的焦点。我们的模型与情节单元框架联系更紧密 (Lehnert, 1981; Goyal et al., 2013),这种框架用情感状态来标注事件。
RMN 是建立在深度复现自动编码器比如等级 LSTM 自动编码器 (Li et al. 2015) 的基础上的;但是,它效率更高,因为用了区间层的矢量平均。它也跟近期的神经话题模型构架 (Cao et al. 2015; Das et al. 2015) 类似,虽然这些模型局限于静态文档表示。我们希望把 RMN 应用到非虚构数据集中;Iyyer et al. (2014) 把神经网络应用到非虚构政治书来预测意识形态。
更一般地,话题模型和相关的生成模型是理解从科学 (Talley et al. 2011) 到政治文本 (Nguyen et al. 2014) 的中心工具。我们展示了 RMN 这类表示学习模型可以和基于 LDA 的模型一样可解释。研究者优先考虑矢量表示的可解释性的其它应用包括文本到视觉的映射 (Lazaridou et al. 2014) 以及词嵌入 (Fyshe et al. 2015; Faruqui et al. 2015。